Using Cline and Ollama with Visual Studio Code
Setting up Cline and Ollama with Visual Studio Code

As developers, we're always looking for ways to enhance our coding workflow with AI assistance. Today, we'll walk through setting up Cline (an AI coding assistant) with Ollama (local LLM runtime) in Visual Studio Code. This powerful combination gives you AI-powered coding assistance while keeping everything running locally on your machine. And yeah It's FREE :)
What You'll Need
Before we dive in, make sure you have:
- Visual Studio Code installed
- Node.js (version 18 or higher)
- At least 8GB of RAM (16GB recommended for larger models)
- A decent GPU (optional but recommended for faster inference)
Step 1: Installing Ollama
On macOS
1# Install via Homebrew
2brew install ollama
3
4# Or download directly from ollama.ai
5curl -fsSL https://ollama.ai/install.sh | sh
On Linux
1# Install script
2curl -fsSL https://ollama.ai/install.sh | sh
3
4# Or via package managers
5# Ubuntu/Debian
6sudo apt install ollama
7
8# Arch Linux
9yay -S ollama
On Windows
- Download the installer from ollama.ai
- Run the installer and follow the setup wizard
- Restart your terminal/PowerShell
Verify Installation
1ollama --version
Step 2: Setting up Ollama Models
Start the Ollama service:
1ollama serve
In a new terminal, download and run your preferred model. Here are some popular options:
For Code Generation (Recommended)
1# CodeLlama - Excellent for code completion and generation
2ollama pull codellama:7b
3
4# DeepSeek Coder - Specifically trained for coding tasks
5ollama pull deepseek-coder:6.7b
6
7# Phind CodeLlama - Optimized for code explanation
8ollama pull phind-codellama:34b
For General Purpose
1# Llama 2 - Good balance of capability and speed
2ollama pull llama2:7b
3
4# Mistral - Fast and capable
5ollama pull mistral:7b
6
7# Code-specific Mistral variant
8ollama pull codestral:22b
Test your model:
1ollama run codellama:7b
Step 3: Installing Cline Extension
- Open Visual Studio Code
- Go to the Extensions view (
Ctrl+Shift+XorCmd+Shift+X) - Search for "Cline"
- Install the Cline extension by the official publisher
- Restart VS Code
Alternatively, install via command line:
1code --install-extension cline.cline
Step 4: Configuring Cline with Ollama
Access Cline Settings
- Open VS Code Command Palette (
Ctrl+Shift+PorCmd+Shift+P) - Type "Cline: Open Settings" and select it
- Or navigate to Settings → Extensions → Cline
Configure Ollama Connection
In the Cline settings:
1{
2 "cline.provider": "ollama",
3 "cline.ollama.baseUrl": "http://localhost:11434",
4 "cline.ollama.model": "codellama:7b",
5 "cline.temperature": 0.3,
6 "cline.maxTokens": 2048,
7 "cline.contextWindow": 4096
8}
Key Configuration Options
Provider Settings:
provider: Set to "ollama"baseUrl: Ollama's default URL (usuallyhttp://localhost:11434)model: The model name you downloaded (e.g., "codellama:7b")
Performance Tuning:
temperature: Controls randomness (0.1-0.5 for code, 0.7-1.0 for creative tasks)maxTokens: Maximum response lengthcontextWindow: How much previous conversation to remember
Alternative Configuration via VS Code Settings UI
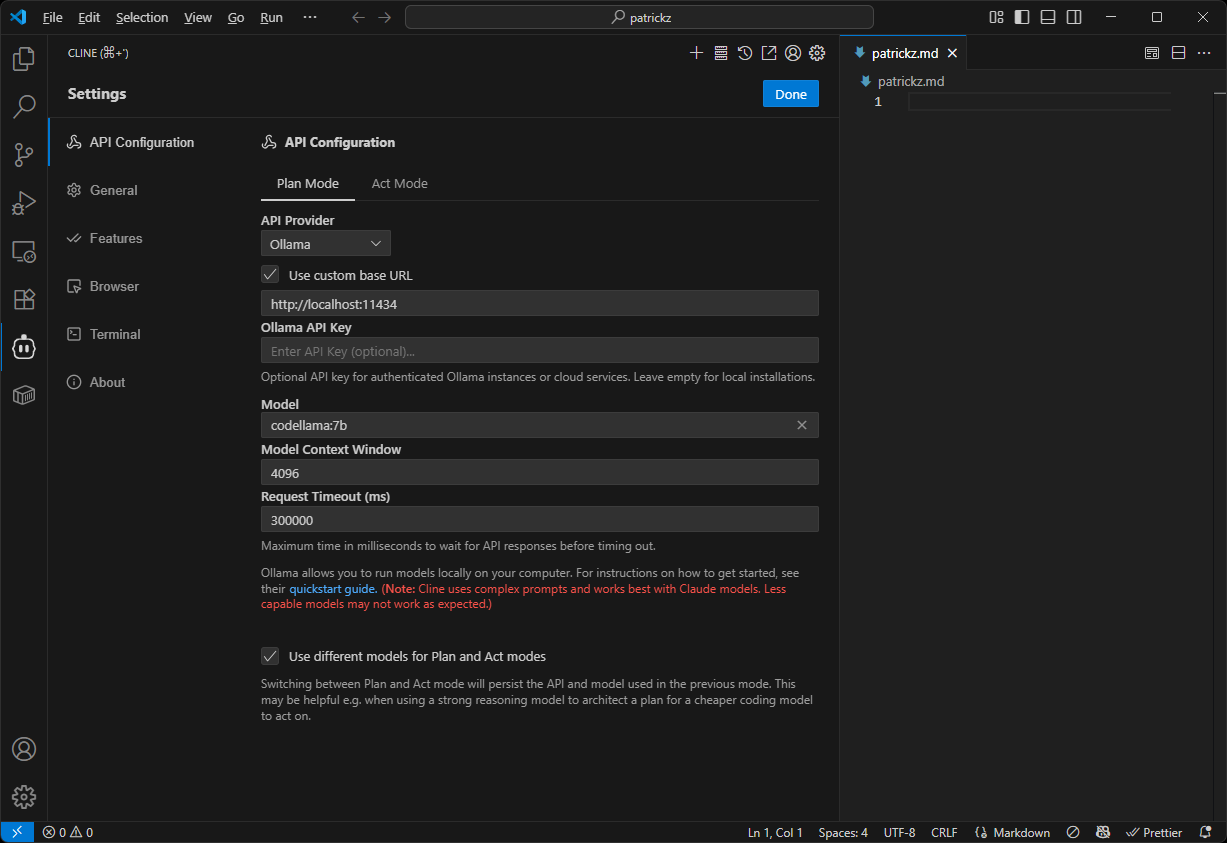
- File → Preferences → Settings
- Search for "Cline"
- Configure the following:
- Cline: Provider → "ollama"
- Cline: Ollama Base URL → "http://localhost:11434"
- Cline: Ollama Model → "codellama:7b" (or your preferred model)
Step 5: Testing Your Setup
Basic Functionality Test
- Open a new file in VS Code (e.g.,
test.py) - Open Command Palette (
Ctrl+Shift+P) - Run "Cline: Start Chat" or use the Cline panel
- Try a simple request: "Write a Python function to calculate fibonacci numbers"
Troubleshooting Common Issues
Cline can't connect to Ollama:
1# Check if Ollama is running
2ps aux | grep ollama
3
4# Restart Ollama service
5ollama serve
6
7# Check port availability
8netstat -an | grep 11434
Model not found error:
1# List available models
2ollama list
3
4# Pull the model if missing
5ollama pull codellama:7b
Slow responses:
- Try smaller models (7B instead of 13B/34B)
- Reduce context window size
- Close other memory-intensive applications
Step 6: Optimizing Your Workflow
Recommended Model Selection by Use Case
For Fast Code Completion:
codellama:7b- Quick responses, good for autocompletiondeepseek-coder:1.3b- Ultra-fast, basic code assistance
For Complex Code Analysis:
codellama:13b- Better understanding, slower responsesphind-codellama:34b- Excellent for debugging and explanations
For General Programming Help:
mistral:7b- Good balance of speed and capabilitycodestral:22b- Specialized for code tasks
Performance Tips
System Optimization:
1# Increase Ollama's memory allocation
2export OLLAMA_HOST=127.0.0.1:11434
3export OLLAMA_MAX_LOADED_MODELS=2
4export OLLAMA_NUM_PARALLEL=2
VS Code Settings:
1{
2 "cline.autoSuggest": true,
3 "cline.inlineCompletion": true,
4 "cline.debounceTime": 300,
5 "cline.enableFileContext": true
6}
Step 7: Advanced Configuration
Custom Model Parameters
Create an Ollama Modelfile for fine-tuned behavior:
1FROM codellama:7b
2
3# Set custom parameters
4PARAMETER temperature 0.2
5PARAMETER top_k 40
6PARAMETER top_p 0.9
7PARAMETER repeat_penalty 1.1
8
9# Custom system prompt for coding
10SYSTEM """
11You are a helpful coding assistant. Provide concise, accurate code solutions.
12Focus on clean, readable code with appropriate comments.
13"""
Apply the custom model:
1ollama create my-code-assistant -f ./Modelfile
2ollama run my-code-assistant
Update Cline to use the custom model:
1{
2 "cline.ollama.model": "my-code-assistant"
3}
Project-Specific Settings
Create .vscode/settings.json in your project:
1{
2 "cline.provider": "ollama",
3 "cline.ollama.model": "deepseek-coder:6.7b",
4 "cline.temperature": 0.1,
5 "cline.enableProjectContext": true,
6 "cline.includeFileTypes": [".js", ".ts", ".py", ".go", ".rs"]
7}
Usage Examples
Code Generation
Prompt: "Create a React component for a user profile card"
Result: Cline will generate a complete React component with props, styling, and proper structure.
Code Explanation
Prompt: "Explain this regex pattern: ^(?:[a-z0-9!#$%&'*+/=?^_{|}~-]+(?:.[a-z0-9!#$%&'*+/=?^_{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")@"
Result: Cline will break down the regex and explain each component clearly.
Debugging Assistance
Prompt: "This function is throwing a null pointer exception, can you help debug it?"
Result: Cline will analyze your code and suggest potential fixes.
Best Practices
Model Management
1# Keep only models you actively use
2ollama list
3ollama rm unused-model:tag
4
5# Update models regularly
6ollama pull codellama:7b
Resource Monitoring
1# Monitor Ollama resource usage
2ollama ps
3
4# Check GPU utilization (if using GPU)
5nvidia-smi
Backup Your Configuration
Save your working Cline configuration:
1# Export VS Code settings
2cp ~/.config/Code/User/settings.json ~/cline-backup-settings.json
Troubleshooting Guide
Common Issues and Solutions
Issue: "Connection refused" error
1# Solution: Ensure Ollama is running
2ollama serve &
Issue: Model responses are too slow
- Switch to a smaller model (7B instead of 13B)
- Reduce context window size
- Close unnecessary applications
Issue: Out of memory errors
1# Solution: Limit concurrent requests
2export OLLAMA_MAX_LOADED_MODELS=1
Issue: Cline suggestions are irrelevant
- Adjust temperature (lower for more focused responses)
- Update your system prompt
- Ensure you're using a code-specific model
Security Considerations
Since everything runs locally:
- ✅ Your code never leaves your machine
- ✅ No API keys or external services required
- ✅ Complete privacy and data control
- ✅ Works offline once models are downloaded
Performance Benchmarks
Based on typical setups:
| Model | Size | Speed | Quality | Best For |
|---|---|---|---|---|
| codellama:7b | ~4GB | Fast | Good | General coding |
| deepseek-coder:6.7b | ~4GB | Fast | Excellent | Code-specific tasks |
| codellama:13b | ~8GB | Medium | Better | Complex analysis |
| phind-codellama:34b | ~20GB | Slow | Excellent | Detailed explanations |
Conclusion
Setting up Cline with Ollama gives you a powerful, privacy-focused coding assistant that runs entirely on your local machine. The combination provides:
- Local AI assistance without cloud dependencies
- Customizable models for different coding tasks
- Privacy and security with no data sharing
- Cost-effective solution with no API fees
Start with a smaller model like codellama:7b to test your setup, then experiment with larger models based on your hardware capabilities and specific needs.
Next Steps
- Explore different models for various programming languages
- Create custom Ollama models fine-tuned for your specific projects
- Set up project-specific Cline configurations
- Integrate with your existing development workflow
Happy coding! 🚀
Have questions or run into issues? The Cline and Ollama communities are very helpful. Check out their respective GitHub repositories and Discord servers for support.